
Social capital—the strength of an individual’s social network and community—has been identified as a potential determinant of outcomes ranging from education to health 1,2,3,4,5,6,7,8 . However, efforts to understand what types of social capital matter for these outcomes have been hindered by a lack of social network data. Here, in the first of a pair of papers 9 , we use data on 21 billion friendships from Facebook to study social capital. We measure and analyse three types of social capital by ZIP (postal) code in the United States: (1) connectedness between different types of people, such as those with low versus high socioeconomic status (SES); (2) social cohesion, such as the extent of cliques in friendship networks; and (3) civic engagement, such as rates of volunteering. These measures vary substantially across areas, but are not highly correlated with each other. We demonstrate the importance of distinguishing these forms of social capital by analysing their associations with economic mobility across areas. The share of high-SES friends among individuals with low SES—which we term economic connectedness—is among the strongest predictors of upward income mobility identified to date 10,11 . Other social capital measures are not strongly associated with economic mobility. If children with low-SES parents were to grow up in counties with economic connectedness comparable to that of the average child with high-SES parents, their incomes in adulthood would increase by 20% on average. Differences in economic connectedness can explain well-known relationships between upward income mobility and racial segregation, poverty rates, and inequality 12,13,14 . To support further research and policy interventions, we publicly release privacy-protected statistics on social capital by ZIP code at https://www.socialcapital.org.
Recent work has argued that social capital may play a central role in shaping important social phenomena such as income inequality and economic opportunity 15,16 . However, a lack of large-scale data on social networks has limited the ability of researchers to understand what types of social capital matter for such outcomes and how we can increase effective forms of social capital. For example, the most widely used dataset to study social networks—the National Longitudinal Study of Adolescent to Adult Health (Add Health)—covers approximately 20,000 students at 132 schools in the United States and, owing to small sample sizes, cannot be disaggregated by school. More recent studies have used large-scale mobile phone data to measure ‘experienced segregation’ 1,17,18,19,20,21 but do not directly observe social interactions between different types of people, a distinction that we show is empirically important.
Here, we use data on the social networks of 72.2 million users of Facebook aged between 25 and 44 years to construct and publicly release (https://www.socialcapital.org) new measures of social capital for each ZIP code in the United States. In a companion paper 9 , we also release data on social capital for each high school (secondary school) and college (university). As in previous research using Facebook data 22,23,24,25,26 (Supplementary Information C.1), we use social network data as a proxy for real-world friendships rather than online interactions per se. As a result, our analysis does not shed light on the effects of online social networks themselves.
We correlate our new measures of social capital with data on economic mobility—children’s chances of rising up the income distribution—across areas and analyse the mechanisms through which social capital and economic mobility are related. We find that the degree to which people with low and high SES are friends with each other (which we term economic connectedness (EC)) is strongly associated with upward income mobility, whereas other forms of social capital are not.
Building on previous work 27,28,29 , we organize measures of social capital into three categories: (1) cross-type connectedness, which is the extent to which different types of people (for example, high income versus low income) are friends with each other 15,30,31,32 ; (2) network cohesiveness, which is the degree to which friendship networks are clustered into cliques and whether friendships tend to be supported by mutual friends 33 ; and (3) civic engagement, which we measure using indices of trust or participation in civic organizations 34,35 .
Cross-type connectedness can be viewed as a form of ‘bridging’ capital, whereas network cohesiveness is more in line with the concept of ‘bonding’ capital 36 . In addition to measuring distinct concepts, these categories of social capital differ in terms of the data they use as inputs. Measures of cross-type connectedness combine data on networks (friendship links) with data on individual characteristics. By contrast, measures of cohesiveness use only data on network links, with no characteristics. Finally, measures of civic engagement do not use data on networks at all and are instead based purely on individual or community-level characteristics (Supplementary Table 6).
We measure these concepts, which are defined more precisely below, using privacy-protected data from Facebook (Methods: ‘Sample construction’ and ‘Privacy and ethics’). We focus on Facebook users with the following attributes: aged between 25 and 44 years who reside in the United States; active on the Facebook platform at least once in the previous 30 days; have at least 100 US-based Facebook friends; and have a non-missing residential ZIP code. We focus on the 25–44-year age range because its Facebook usage rate is greater than 80% (ref. 37 ). On the basis of comparisons to nationally representative surveys and other supplementary analyses, our Facebook analysis sample is reasonably representative of the national population (Methods: ‘Benchmarking’). We use the Facebook data to obtain information on friendships, locations (ZIP code and county), and individuals' SES and their parents' SES. These variables are described in detail in the Methods (‘Variable definitions’).
Many theoretical studies have shown how connections to more educated or affluent individuals can be valuable for transferring information, shaping aspirations and providing mentorship or job referrals 15,30,31,38,39,40,41,42,43,44 . Consistent with these models, empirical studies have documented that social ties to well-resourced individuals can materially affect economic and labour market outcomes 3,4,5,45 . Motivated by this literature, we begin by measuring connectedness across different types of people, focusing on economic connectedness: the extent to which people with low and high SES are friends with each other.
Social scientists have measured SES using many different variables, ranging from income and wealth to educational attainment, occupation, family background, neighbourhood and consumption 46 . To capture these varied definitions, we compute the SES for each individual in our analysis sample by combining several measures of SES, such as average incomes in the individual’s neighbourhood and self-reported educational attainment (see the ‘Privacy and ethics’ section of the Methods for a discussion of how user privacy was protected during this project). We combine these measures of SES into a single SES index using a machine-learning algorithm (Methods (‘Variable definitions’) and Supplementary Information B.1). We then calculate each individual’s percentile rank in the national SES distribution relative to others in their birth cohort. Although we do not observe individuals’ incomes directly, we show that our SES rankings are highly correlated with external, publicly available measures of income across groups (for example, ZIP codes, high schools, and colleges). We also show that using simpler measures of SES, such as median household income in an individual’s ZIP code, produces very similar results to those reported below.
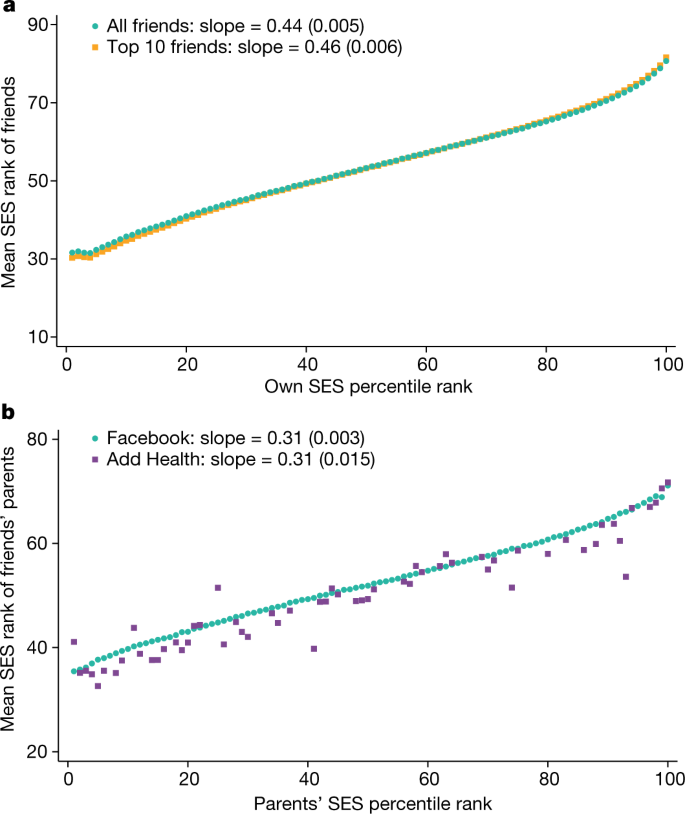
Figure 1a plots the mean SES rank of individuals’ friends against their own SES ranks. There is strong homophily, whereby individuals with higher SES are friends with higher-SES people. A one percentile point increase in one’s own SES rank is associated with a 0.44 percentile point increase in the SES rank of one’s friends on average. The relationship is almost linear between the 10th and 90th percentiles of the SES distribution, with a slope of 0.41 in that range. The slope rises to 0.98 between the 90th and 100th percentiles, which shows that the highest-SES individuals tend to have particularly high-SES friends. These estimates of homophily are similar (slope of 0.46 for full range, 1.02 between the 90th and 100th percentiles) when we restrict the analysis to an individual’s ten closest friends (defined on basis of the frequency of public interactions such as likes, tags, wall posts and comments). This result shows that our estimates are not significantly affected by the strength of friendships or the number of Facebook friends that people have.
For our analyses below, it is useful to measure connections between individuals in different parts of the SES distribution. For simplicity, in our main analysis, we separate individuals into two groups on the basis of their SES: below-median and above-median SES (which we refer to as low SES and high SES, respectively, below). On average, 38.8% of the friends of below-median-SES individuals have above-median SES, whereas 70.6% of the friends of above-median-SES individuals have above-median SES. As 50% of individuals have above-median SES by definition, high-SES friends are under-represented by 22.4% ( \(1-\frac=0.224\) ) among low-SES individuals relative to their share in the population. By contrast, high-SES friends are over-represented by 41.2% among high-SES individuals ( \(\frac-1=0.412\) ). Note that the share of high-SES friends for low-SES and high-SES individuals averages to 54.7% rather than 50% because high-SES people have more friends than low-SES people on average (Extended Data Table 1).
If high-SES and low-SES individuals were to make friendships independent of SES (that is, there were no homophily by SES) and also were to make the same number of friends on average, then 50% of low-SES individuals’ friends would have high SES. In practice, above-median-SES individuals have 25.4% more friends than below-median-SES individuals on average (Extended Data Table 1). If high-SES people continue to make 25.4% more friends than low-SES people, but friendships were formed independent of SES, the share of high-SES friends among low-SES individuals would be \(\frac=55.6 \% \) . Relative to that benchmark, low-SES individuals make 30.2% fewer high-SES friends than they would in the absence of homophily.
We go beyond the two-group median split by examining connections between individuals in different deciles of the SES distribution. Extended Data Table 1 presents a matrix of intradecile friendship rates, which shows the likelihood of friendship formation for people from different deciles of the SES distribution. Connectedness is lower between deciles that are further apart. For instance, top-decile friends are under-represented among people in the bottom decile by 75% relative to their population share ( \(1-\frac=0.75\) ). This value is more than three times larger than the corresponding 22.4% under-representation of above-median friends among below-median individuals.
In addition to measuring economic connectedness among adults, we use parent–child linkages to analyse EC based on the childhood friendships of individuals from different family backgrounds. Social capital during individuals’ formative years may be particularly relevant for intergenerational income mobility 30 .
We measure childhood EC by analysing homophily in friendships made in high school by parents’ SES (Methods: ‘Measuring connectedness’). Figure 1b plots the mean parental SES rank of a given individual’s five closest friends in high school against the SES rank of the individual’s own parents. There is less homophily by parental SES during childhood than by own SES in adulthood, with a slope of 0.31 instead of 0.44. Much of this difference in slopes arises from the fact that SES in adulthood among friends from high school is more similar than their parents' SES, perhaps because children who befriend each other tend to follow similar trajectories 9 .
The series represented by squares in Fig. 1b shows analogous estimates of homophily by parental SES rank among high school students using data from Add Health, a representative survey of students that contains self-reported information on close friendships (Supplementary Information A.5.2). We obtain highly similar point estimates of homophily (slope = 0.31) by parental SES rank among high school friends in the Facebook and Add Health data. This comparison suggests that selection biases in Facebook usage or measurement error in friendship links and SES ranks do not substantially distort our estimates of homophily.
The Facebook dataset, which is about 3,500 times larger than the Add Health sample, offers adequate precision and information to allow us to measure EC not just at the national level but also within specific communities, such as a given neighbourhood or school. We define the level of economic connectedness in a community as the average share of above-median-SES friends among below-median-SES members of that community divided by 50% to quantify the average degree of under-representation of high-SES friends among low-SES people (an algebraic definition is provided in the Methods: ‘Measuring connectedness’). A value of 0 for EC implies that a network has no connections between low-SES and high-SES people, whereas a value of 1 implies that low-SES people have an equal number of low-SES and high-SES friends. Although we focus on economic connectedness among low-SES individuals in particular, which we refer to simply as EC, we also construct and release analogous measures of community-level economic connectedness for high-SES individuals.
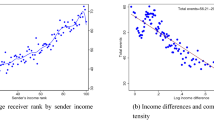
Figure 2a maps EC by county in the United States. EC varies significantly across areas. Counties in the bottom decile of connectedness have EC values less than 0.58. That is, below-median-SES individuals have about 42% fewer above-median-SES friends than one would expect in the absence of homophily. Counties in the top decile have EC values of 1.05 or higher, approximately commensurate to what one would expect on the basis of random sampling of friends from the national distribution, adjusting for the fact that high-SES people make more friends, as discussed above. This geographical variation in connectedness is partially driven by differences in the share of high-SES individuals in an area and partly by differences in the rates at which low-SES individuals befriend high-SES individuals in their area. We decompose the relative contributions of these two factors, which we refer to as exposure and friending bias, in the companion paper 9 .
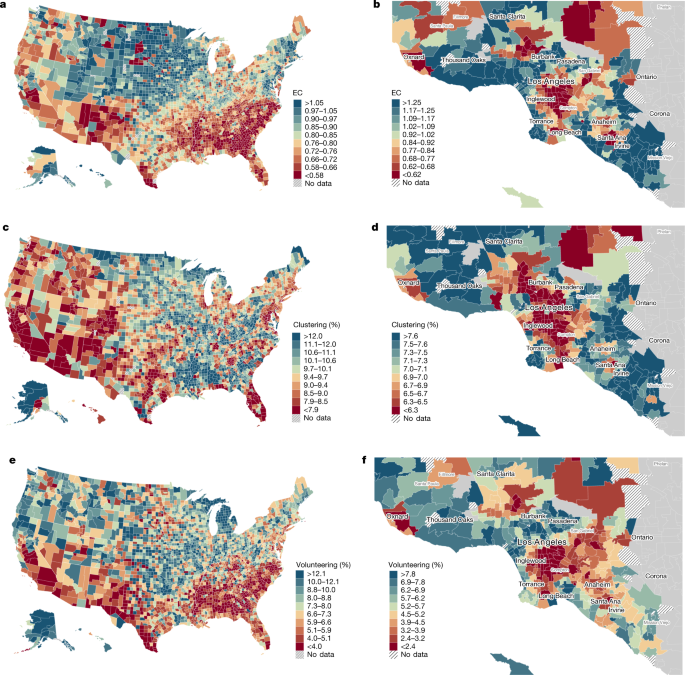
EC is generally lowest in the Southeast, the Southwest and industrial cities in the Midwest. It is highest in the rural Midwest and on the East Coast. The mean standard error of the county-level EC estimates is 0.004 (Methods (‘Measuring connectedness’) and Supplementary Information B.3), which implies that nearly all of the variation in Fig. 2a reflects true differences in EC across areas rather than sampling error.
EC varies not just across counties but also across neighbourhoods within counties: 42% of the variation in EC across ZIP codes is within counties. Figure 2b illustrates this local variation by mapping EC by ZIP code (formally, ZIP code tabulation areas) in the Los Angeles metropolitan area (analogous maps for all ZIP codes in the United States are available at https://www.socialcapital.org). EC ranges from 0.62 to 1.25 between ZIP codes at the 10th and 90th percentiles of the EC distribution within the Los Angeles metro area (Los Angeles, Orange and Ventura counties). EC is lowest in the lowest-income neighbourhoods of Los Angeles, such as Watts in central Los Angeles, where EC is 0.45. EC is generally higher in higher-income areas, but there is significant variation in EC even within those areas, with some places (such as Echo Park) having relatively low EC despite having many high-SES residents.
More broadly, looking outside Los Angeles, almost none of the lowest-income ZIP codes in the United States exhibit high levels of EC. It may be that there is little scope for people with low SES to connect with individuals with higher SES if there are few such people in the vicinity, echoing Blau's observation that “persons cannot associate without having opportunities for contact” 47 . In our analysis, this point is an empirical result rather than a mechanical consequence of contact because low-SES individuals in low-income areas could in principle befriend high-SES people outside their neighbourhoods. In practice, such connections appear to be relatively rare. However, the presence of high-SES neighbours does not guarantee that low-SES people connect with those individuals, as many higher-income neighbourhoods still have EC substantially below 1.
The spatial patterns documented above are robust to the way in which economic connectedness is measured. For example, Supplementary Table 1 shows that similar spatial patterns for EC are obtained when restricting attention to individuals' ten closest friends (correlation = 0.99 across counties). Similarly, the mean friend rank of individuals at the 25th percentile of the SES distribution, a measure that controls for differences in the SES distributions within the below-median and above-median groups, has an across-county correlation of 0.98 with our baseline EC measure. The share of top-quintile-SES friends among bottom-quintile-SES individuals in a county has a correlation of 0.74 with our baseline below- versus above-median EC measure across counties. Childhood EC also exhibits broadly similar spatial patterns. We analyse two measures of childhood EC: one constructed for Facebook users from the SES of parents of high school friends and the other constructed for a sample of current 13–17 year olds who use Instagram (Methods: ‘Measuring connectedness’). We obtain across-county correlations of 0.61 for the Facebook childhood EC measure and 0.82 for the Instagram measure with our baseline EC measure (Supplementary Table 1). The high correlation with EC measured using Instagram for recent birth cohorts suggests that differences in economic connectedness across areas are relatively stable over time, which is consistent with the high degree of serial correlation in our baseline county-level EC measure across birth cohorts (Supplementary Fig. 1).
We also measure connectedness between individuals who use English as their primary language versus those who do not, and individuals between the ages of 25 and 34 years versus individuals between the ages of 35 and 44 years. Language and age connectedness exhibit different spatial patterns from EC (Extended Data Fig. 1). For example, the across-county correlation between language connectedness and EC is only 0.10 (Table 1). Hence, it is not simply that some areas exhibit high levels of connectedness across all types of individuals; rather, the degree of connectedness varies across different characteristics.
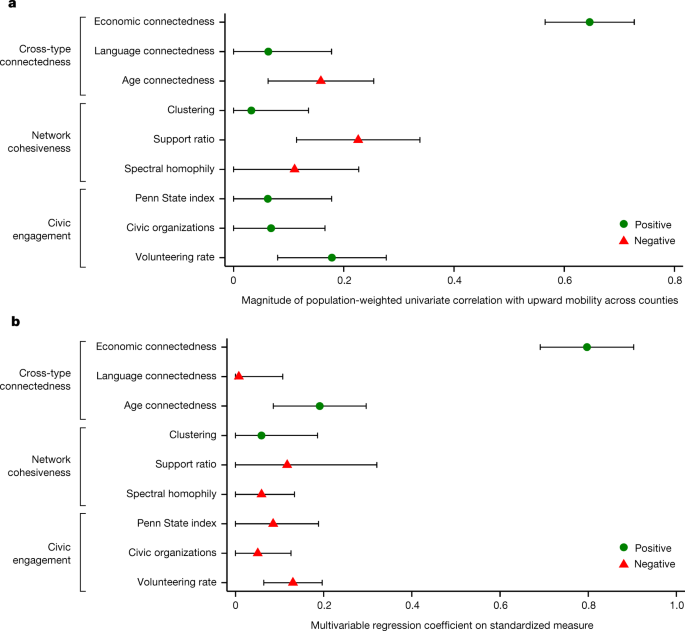
Figure 4 shows the relationship between EC and mobility non-parametrically by presenting a scatter plot of upward income mobility versus EC for the 200 most populous counties. Children who grow up in counties where low-SES individuals have more high-SES friends tend to have much higher rates of upward mobility. As an example, low-SES individuals have a much larger share of high-SES friends in Minneapolis (49%, corresponding to an EC of 0.98) compared with Indianapolis (32%, EC of 0.65). Correspondingly, children who grow up in low-income families have much higher incomes in adulthood in Minneapolis than in Indianapolis. In Minneapolis, children reach the 43rd percentile of the household income distribution on average at age 35 years (roughly US$34,300 in 2015), compared with the 34th percentile ($24,700) in Indianapolis.
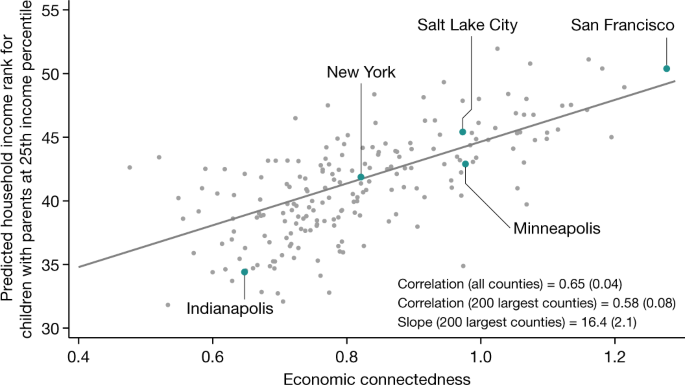
On average, an increase in EC of 0.5 units (equivalent to raising the share of high-SES friends among low-SES people from 25% to 50%, and approximately equal to the difference in EC between the 10th and 90th percentile counties) is associated with an 8.2 percentile increase in children’s incomes in adulthood. This is a large difference: for context, note that children with high-income (above-median) parents end up 17 percentiles higher in the household income distribution on average than children with low-income (below-median) parents (Extended Data Fig. 2). There are similarly strong associations between EC and many other outcomes related to social mobility, such as high school completion rates and teenage birth rates (Extended Data Fig. 3).
Returning to Fig. 3a, other measures of connectedness across groups—between non-English and English speakers or between younger and older individuals—are less strongly associated with upward mobility. Communities with greater connectedness across groups in general do not necessarily have higher levels of upward mobility. Instead, connections across class lines are what appear to matter.
Measures of network cohesion (for example, clustering and support ratios) also do not strongly correlate with observational measures of upward income mobility. This is because there are many areas that exhibit highly cohesive networks—and thus might be thought of as tightly knit communities—but that nevertheless have low levels of EC and correspondingly low levels of upward mobility. A potential explanation for this pattern is that although those communities have strong social connections among their predominantly low-income residents (bonding social capital), they are not well connected to individuals from higher-SES backgrounds who can provide the types of resources, opportunities and information 30,31 needed to rise economically (bridging social capital).
Finally, we examine associations between economic mobility and measures of civic engagement. The widely used Penn State index 63 of participation in civic organizations has a correlation of 0.06 across counties with upward mobility. There are similarly weak associations of upward mobility with our measures of the density of civic organizations and volunteering rates. The difference between these findings and previous work that has found stronger associations between civic engagement and economic mobility is primarily because we weight our correlations by the number of children with below-national-median parental income. As a result, rural areas—where civic engagement is more strongly correlated with mobility—receive lower weight in our correlations (Supplementary Information C.2).
When we regress measures of upward mobility on standardized versions of all of the social capital measures together, EC remains the strongest predictor of upward mobility by a significant margin. By contrast, measures of civic engagement and network cohesiveness have coefficients near zero (Fig. 3b). Furthermore, a Lasso regression selects EC as the first social capital measure to include and places greater weight on EC than on other measures (Supplementary Fig. 2a). Moreover, the incremental R 2 of including EC conditional on all the other social capital measures is an order of magnitude larger than the incremental R 2 of including any of the other measures (Supplementary Fig. 2c).
When studying variation across ZIP codes instead of counties in the United States, we find very similar correlations between upward income mobility and social capital measures (Extended Data Table 2 and Supplementary Fig. 3). In particular, upward mobility is highly correlated (0.69) with EC across ZIP codes (Supplementary Fig. 4), but more weakly correlated with all the other social capital measures. Going from the 10th to the 90th percentile ZIP code in the United States in terms of EC is associated with an 11 percentile increase in the mean adult income rank of children growing up in low-income families. This value is comparable to the 12.6 percentile difference in mean income ranks between Black children and white children with low-income parents 73 .
Next, we examine the association between social capital measures and upward mobility across ZIP codes within the same county to assess whether the ZIP-code-level relationships differ across counties. The ZIP-code-level correlation between EC and mobility is strongly positive within nearly all counties. By contrast, there is substantial heterogeneity in the ZIP-code-level relationships between other measures of social capital and mobility across counties. Extended Data Fig. 4a illustrates this by presenting binned scatter plots of the relationship between upward mobility and clustering coefficients by ZIP code across four cities in Ohio: Akron, Cleveland, Columbus and Youngstown. In Cleveland and Columbus, where baseline levels of clustering are relatively low, neighbourhoods with higher clustering coefficients have significantly higher levels of upward income mobility. But in Akron and Youngstown, which generally have higher levels of clustering, clustering and upward mobility are negatively correlated. Hence, it is not that clustering coefficients have no signal in predicting economic mobility; instead, their relationship with mobility varies across places, in part depending on their average levels of clustering.
The relationship between EC and mobility is much more stable across the same four cities, as shown in Extended Data Fig. 4b. The relationships between clustering coefficients and EC closely match those for mobility. In Cleveland and Columbus, clustering coefficients and EC are positively related, whereas in Akron and Youngstown, they are negatively related (Extended Data Fig. 4c). Building on these examples, we find that clustering is often positively correlated with EC and mobility when clustering is low, whereas it is often negatively correlated with both EC and mobility when levels of clustering are high. These patterns suggest that EC may mediate the relationship between other social capital measures and mobility. That is, the links between other social capital measures and mobility might run through economic connectedness.
Extended Data Fig. 4d generalizes the four examples by plotting the distributions of the correlations between upward mobility and various measures of social capital across ZIP codes within the 250 most populous counties in the United States. For EC, the distribution sharply peaks around 0.7, showing that economic connectedness and mobility are positively correlated across ZIP codes in nearly all counties. By contrast, the other social capital measures exhibit more diffuse distributions across counties. Notably, these differences are not just due to sampling error in the correlations. Adjusting for noise by calculating the reliability of the estimates and the standard deviation of the latent signal distribution produces similar conclusions (Supplementary Table 2).
To summarize, measures of social capital that are based solely on the structure of the network graph (network cohesion) or purely on individuals’ civic behaviours (civic engagement) do not have robust associations with observational measures of economic mobility across areas. Measures that combine data on networks with information on SES have stronger and more stable relationships with economic mobility.
Having established that EC stands out among social capital measures as a strong predictor of economic mobility, in the remainder of the paper we focus on understanding the source of this correlation; that is, why more economically connected areas tend to have higher rates of economic mobility.
There are many theories for why economic connectedness could have a positive causal effect on upward income mobility. For example, economic mobility might be facilitated by connections to people who can shape aspirations or provide access to information and job opportunities 30,32 . This interpretation is consistent with the argument that bridging capital—a concept that encompasses EC—is particularly valuable for ‘getting ahead’ 36 . However, there are also many alternative explanations for the correlation between EC and mobility that do not rely on a causal effect of connectedness on mobility. We evaluate three such possibilities in turn—reverse causality, selection effects, and omitted variables—with the broader aim of better understanding the channels through which connectedness and mobility are related.
The first alternative explanation for the correlation between connectedness and mobility we consider is reverse causality, whereby greater economic mobility could lead to greater EC. Specifically, in our baseline analysis, we correlated rates of upward income mobility with EC measured among adults. Because friendships and SES are measured in adulthood, economic connectedness may itself be influenced by rates of intergenerational mobility. For example, in places with high upward mobility, many children from low-SES families have high incomes as adults and may retain friendships with individuals who remain at a low SES. This would lead to high-mobility areas having a high rate of friendships among people with different SES in adulthood, even in the absence of any effect of economic connectedness on mobility.
To assess the importance of reverse causality, we examine the association between economic mobility and childhood EC, on the basis of childhood friendships and parental SES. Because childhood friendships are made before people start working, they cannot be directly influenced by rates of economic mobility. We measure childhood EC using two sources of data, each of which has benefits and drawbacks (Methods: ‘Measuring connectedness’). The first is based on the high school friends and parental SES of individuals in our primary Facebook analysis sample. The second uses data from Instagram for individuals aged 13–17 years in 2022, measuring parental SES based on the teenagers’ residential ZIP codes and mobile phone models.
The correlation between upward mobility and childhood EC across counties remains high with both of these measures: 0.44 using parental SES in the Facebook data and 0.62 using the Instagram data (Extended Data Table 2). Since upward mobility remains strongly correlated with childhood EC, any causal effects of mobility on connectedness must account for, at most, a small share of the correlation between the two variables.
A second potential non-causal explanation for the link between economic connectedness and mobility is selection. Specifically, one might be concerned that the types of families who live in high-EC areas may inherently have higher rates of mobility (for example, because they have more education or wealth), independent of where they live. For example, the types of low-income families who choose to live in high-EC areas may have demographic characteristics or make other choices that increase their children’s rates of upward mobility even in the absence of any causal effect of EC on outcomes.
One of the most salient forms of residential sorting in the United States is segregation by race and ethnicity. Such segregation could lead to a correlation between EC and mobility. For example, areas with larger Black populations tend to have lower levels of EC (Supplementary Table 3). Because Black Americans have lower rates of upward mobility than white Americans 73 —which could be due to factors such as discrimination that are unrelated to differences in EC—differences in racial composition across neighbourhoods could induce a spurious association between EC and mobility when pooling across races.
The simplest way of assessing the importance of differences by race would be to replicate our baseline correlations conditioning on race, for instance by correlating upward mobility and connectedness among Black individuals. As a feasible alternative in the absence of individual-level data on race, we focus on counties or ZIP codes where most of the residents are of the same race (based on publicly available data from the Census). We then correlate race-specific measures of economic mobility 72 with EC (pooling all racial groups) within these areas.
Extended Data Table 3 reports the results of this analysis. Column 1 shows that the correlation between upward mobility for white individuals and overall EC is 0.68 in counties where at least 80% of residents are white (which have a mean white share of 90%). The correlation is similar (0.69) in counties where at least 90% of residents are white, and the mean white share is 95% (column 2). Columns 3 and 4 show that results are similar at the ZIP-code level. In ZIP codes where at least 90% of residents are white, the correlation between upward mobility and EC is 0.69. Columns 5 and 6 show similarly strong correlations between upward mobility for Black people and EC in ZIP codes in which residents are predominantly Black. Columns 7 and 8 show smaller (although not statistically distinguishable) correlations between upward mobility for Hispanic people and EC in the few ZIP codes in which residents are predominantly Hispanic. Note that we can only perform this analysis at the ZIP-code level for Hispanic and Black individuals because there are very few counties that have more than 80% Black or Hispanic residents.
The results in Extended Data Table 3 show that economic connectedness remains highly correlated with economic mobility even conditional on race, which implies that segregation by race is unlikely to be the primary driver of the observed correlation between EC and mobility overall. Relationships between mobility and other measures of social capital also remain similar when restricting the sample to areas in which one race forms an overwhelming share of the population (Supplementary Fig. 5).
Of course, there are many dimensions beyond race on which families may sort across neighbourhoods, such as their underlying human capital or their propensity to invest in their children’s education. To test for sorting on such dimensions, many of which are unobservable, one would ideally randomly assign families to low-EC and high-EC areas—thereby ensuring that families in high-EC and low-EC areas are comparable—and examine whether their children’s outcomes differ in adulthood. We approximate this experiment using quasi-experimental estimates of the causal effect of growing up for an additional year in each county in the United States on household incomes in adulthood from Chetty and Hendren 74 . That study used variation in the age at which children move across counties to identify the causal effect of growing up in each county for children with parents at the 25th percentile of the income distribution. Under the identification assumption that the timing of moves is unrelated to children’s potential outcomes—an assumption validated in a series of experimental and quasi-experimental studies 75,76,77,78 —differences in adult incomes for children who move at younger versus older ages to a given county reveal its causal effect on economic mobility.
We use Chetty and Hendren's estimates to analyse the relationship between the causal effects of counties on upward mobility and EC. We measure the causal effect of each county as the mean change in an individual’s percentile income rank from growing up from birth (for 20 years) in that county instead of the average county in the United States 75 . Extended Data Fig. 5 presents a binned scatter plot of the causal effects of counties on upward mobility against their EC. Higher EC counties have larger causal effects on upward mobility, with a correlation of 0.44 (s.e. = 0.06) after correcting for sampling error in the causal effect estimates (Methods: ‘Correlations’). In a multivariable regression of counties' causal mobility effects on all our social capital measures, EC remains highly correlated with causal effects on mobility. By contrast, most other social capital measures do not exhibit significant associations (Supplementary Fig. 6).
The slope of the relationship shown in Extended Data Fig. 5 implies that growing up from birth in a county with 1 unit higher EC increases income in adulthood by 9.8 percentiles (a 30.7% increase relative to mean income ranks) for children of parents with low income. This estimate implies that moving at birth from the 10th to 90th percentile ZIP code in terms of EC—a move associated with an increase in EC of 0.57—would increase children’s household income in adulthood by 17.5% on average. As another benchmark, note that the average difference in EC between low- and high-SES individuals is 0.636. If low-SES children were to grow up in counties with EC comparable to the average high-SES child, their incomes would increase on average by 0.636 × 30.7 = 19.5% (equivalent to 6.23 percentiles). This increase in income would close about 37% of the current 17 percentile gap in income in adulthood between children with parents at the 25th and 75th percentiles of the income distribution.
We conclude that the correlation between EC and mobility is not driven simply by differences in the types of families who live in high EC areas. Instead, growing up in an area with higher EC causes significantly higher rates of upward mobility.
Higher EC areas may generate higher levels of mobility for two reasons: either economic connectedness itself has a causal effect on mobility or high-EC places have other characteristics (for example, better schools) that generate higher levels of mobility. As a step towards distinguishing these two explanations, we compare the relative explanatory power of EC and the strongest neighbourhood-level predictors of economic mobility identified in previous work.
We begin by analysing incomes across neighbourhoods. Several studies have shown that areas with lower incomes and more highly concentrated poverty have lower rates of economic mobility 11,79 . Motivated by such findings, many place-based policies use high poverty rates as a marker to identify low-opportunity neighbourhoods that are eligible for special tax credits and resources, and recent work has sought to help families move to lower-poverty neighbourhoods to improve their economic prospects 80 .
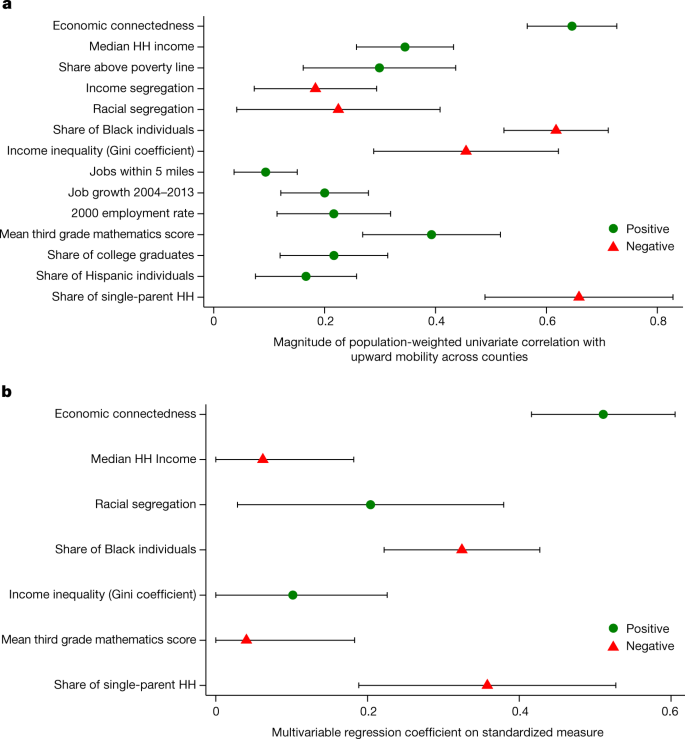
Figure 5a shows univariate county-level correlations between upward mobility and measures of income and various other neighbourhood characteristics (results at the ZIP-code level, shown in Supplementary Fig. 4b, are similar). The share of individuals above the poverty line and median household incomes have correlations of 0.3–0.35 with upward mobility across counties. When we regress upward income mobility on both EC and measures of local income levels (poverty rates or median household incomes), connectedness remains a strong predictor of upward mobility. By contrast, measures of local income levels lose much of their predictive power at both the county and ZIP code levels (Table 2 (EC versus median income and poverty rates) and Supplementary Figs. 7 and 8).
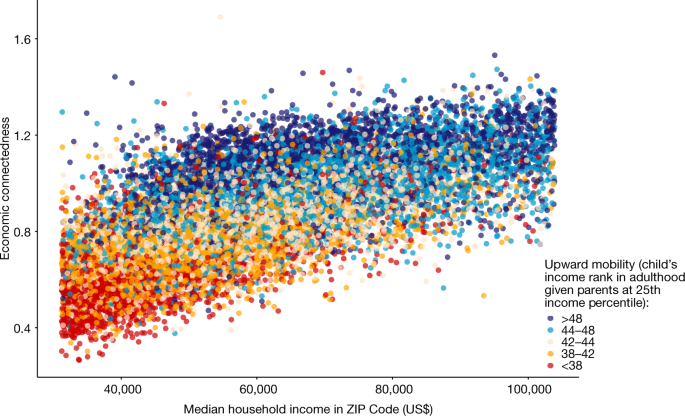
Although local income levels explain little of the relationship between EC and outcomes for children starting out in low-income (25th percentile) families, they do appear to mediate the relationship between connectedness and outcomes for children from high-income (75th percentile) families. We illustrate this result in Extended Data Fig. 6a. As a reference, the series in orange circles presents a county-level binned scatter plot of upward mobility against EC for individuals with low SES. This series is similar to the scatter plot in Fig. 4, except that we include all counties and group them into 20 equal-sized bins on the basis of their level of EC to show the conditional expectation of upward mobility given EC non-parametrically. Consistent with the pattern in Fig. 4, there is a strong positive slope of 18.2.
Now consider the relationship between the average income ranks in adulthood of children with parents at the 75th percentile and the share of low-SES friends that high-SES individuals have. This relationship (plotted in blue circles) is flatter than that for low-SES individuals. A 1 unit increase in cross-group connectedness—defined here as twice the share of low-SES friends among high-SES individuals—is associated with an 8.6 percentile reduction in mean income rank for children with parents at the 75th percentile. Notably, after controlling for the share of high-SES individuals in the county, greater cross-group EC remains strongly positively associated with outcomes for children with parents at the 25th percentile (as established above), but is now uncorrelated with the economic outcomes for children with parents at the 75th percentile (Extended Data Fig. 6b). A potential explanation for this pattern is that greater interaction between low-SES and high-SES households conditional on the income mix in an area benefits lower-income people without harming those with higher incomes; however, greater income mixing (integration) benefits lower-income people partly at the expense of higher-income people by redistributing public goods (for example, local public school funding) from people with higher incomes to people with lower incomes. These results raise the possibility that more economically connected communities can benefit lower-income households with limited adverse impacts on those with higher incomes, particularly if increasing cross-SES connections does not require changing the income mix or resources in an area.
Going beyond average income levels, previous research has also shown that in counties where people of different incomes or racial backgrounds live in separate neighbourhoods, levels of economic mobility are generally lower. Indices of segregation by income and race (constructed from Census data using standard methods 81 ; Supplementary Information A.5.1) have negative correlations of 0.17–0.21 with economic mobility across counties, significantly lower than the correlation of 0.65 observed with EC. Hence, using network data to directly measure interaction (rather than using residential location as a proxy) adds considerable explanatory power for understanding economic mobility. Moreover, when we regress upward mobility on both EC and segregation measures, connectedness remains a strong predictor of upward mobility. By contrast, the segregation indices lose their predictive power (Table 2 (EC versus segregation and inequality) and Supplementary Fig. 9).
Previous work has established that Black individuals living in neighbourhoods with a larger Black population have poorer educational and economic outcomes on average 12 . We replicate these results in the odd-numbered columns of Table 2 (EC versus share of Black residents) by regressing upward income mobility for Black people and white people on the share of Black residents in an area (for both counties and ZIP codes). The corresponding even-numbered columns show that controlling for EC eliminates or even reverses the relationship between the share of Black residents and rates of upward mobility (Supplementary Fig. 10). Areas with a larger Black population tend to have lower levels of EC (Supplementary Table 3), and this relationship accounts for the negative correlation between the share of Black residents and rates of mobility.
Research has also found a strong negative correlation between income inequality within a generation (measured, for example, using the Gini coefficient) and upward mobility across generations, coined the ‘Great Gatsby curve’ 13,14 . Controlling for EC essentially eliminates this relationship (columns 5 and 6 of Table 2 (EC versus segregation and inequality) and Supplementary Fig. 9). Greater income inequality is associated with less EC, and that relationship largely explains the negative correlation between inequality and mobility. In short, a lack of economic connectedness may be a key reason that upward mobility is lower in areas with larger Black populations and greater inequality 82 .
Finally, we turn to other factors that have been explored in previous work, ranging from the quality of local schools to job availability to measures of family structure. EC is more strongly correlated with upward economic mobility than almost all of those characteristics in univariate specifications (Fig. 5a). We also estimate a multivariable regression of upward mobility on EC along with other predictors that have the highest univariate correlations with mobility. In this analysis, EC is the strongest predictor of upward mobility (Fig. 5b) and has the largest incremental R 2 (Supplementary Fig. 2d). EC is also among the first variables—along with the share of single parents—that are chosen by a Lasso regression as predictors of economic mobility (Supplementary Fig. 2b).
In summary, places with higher levels of EC generate higher levels of economic mobility, even when controlling for the strongest neighbourhood-level predictors of economic mobility identified in prior research. Moreover, the relationships between these other neighbourhood characteristics and mobility become much weaker once we control for EC, which indicates that the links between those factors and mobility may run through their impacts on EC. These findings suggest that other observable neighbourhood characteristics do not explain why higher EC areas generate higher levels of upward mobility, calling for further focus on causal mechanisms through which economic connectedness itself may affect mobility.
Measuring social capital has proven to be more challenging than measuring other forms of capital, such as financial or human capital. Data from online social networking platforms offer a path to solving this problem. The new measures of social capital constructed here provide a rich picture of how social capital varies across areas in the United States. Different notions of social capital—connectedness across socioeconomic lines, the cohesiveness of a community and civic engagement—exhibit highly different spatial patterns. Many communities are rich in one form of social capital but poor in others.
Distinguishing these forms of social capital is important because some types of social capital are more correlated with certain outcomes than others. For instance, economic connectedness (EC)—the share of high-SES friends among low-SES people—is strongly associated with upward income mobility, whereas other forms of social capital are not. Areas with higher EC have large positive causal effects on children’s prospects for upward mobility. We caution, however, that this finding does not imply that EC is the best or most important measure of social capital in general. EC may be the best predictor of economic mobility because mobility is essentially a measure of the degree to which individuals can increase their own SES, making it natural that links to higher-SES individuals are related to that outcome. This is consistent with hypotheses that bridging capital is useful specifically for getting ahead (rather than simply getting by) 36,83 . For other outcomes, other social capital indices that we construct here may be stronger predictors. For example, differences in life expectancy among individuals with low income across counties are more strongly predicted by network cohesiveness measures (clustering coefficients and support ratios) than EC (Supplementary Fig. 11 and Supplementary Information C.3).
Our analysis raises three sets of questions for future research. First, it would be useful to conduct systematic studies of the forms of social capital that matter for other outcomes; for example, to determine which forms of social capital matter for health behaviours or the formation of political preferences. The publicly available statistics constructed here can be used to study many such questions.
Second, it would be valuable to build on the methods developed here and construct analogous measures of social capital beyond the United States, either using social network data or other sources of network information such as financial transactions or mobile phone data 84 . Although many of the lessons obtained from our analysis of the United States are likely to generalize more broadly, international comparisons would enrich our understanding of social capital and its determinants.
Finally, it would be useful to directly study whether efforts to increase economic connectdness can increase intergenerational income mobility. Doing so requires an understanding of the determinants of EC and potential interventions to increase it. We address these questions in the companion paper 9 , in which we study why economic connectedness varies with SES and how we can increase connectedness among individuals with low SES.
This section describes the methods used to generate the data analysed in this paper. A server-side analysis script was designed to automatically process the raw data, strip the data of personal identifiers, and generate aggregate results, which we analyzed to produce the conclusions in this paper. The script then promptly deleted the raw data generated for this project (see the Privacy and Ethics section).
We work with privacy-protected data from Facebook. Survey data show that more than 69% of the US adult population used Facebook in 2019, and about three-quarters of those individuals did so every day 37 . The same survey also found that Facebook usage rates are similar across income groups, education levels and racial groups, as well as among urban, rural and suburban residents; they are lower among older adults and slightly higher among women than men.
Starting from the raw Facebook data as of 28 May 2022, our primary analysis sample was constructed by limiting the data to users aged between 25 and 44 years who reside in the United States, were active on the Facebook platform at least once in the previous 30 days, had at least 100 US-based Facebook friends and had a ZIP code. Our final analysis sample consists of 72.2 million Facebook users who constitute 84% of the US population between ages 25 and 44 years (based on a comparison to the 2014–2018 American Community Survey (ACS)). We focus on the 25–44-year age range because previous work 37 has documented that its Facebook usage rate is above 80%, higher than for other age groups. In addition, the ACS publicly releases demographic data for certain age groups, one of which is ages 25–44 years, which enables us to compare our sample with the full population as well as to use ACS aggregates to predict SES (‘Variable definitions’).
We do not link any external individual-level information to the Facebook data. However, we use various publicly available sources of aggregate statistics to supplement our analysis, including data on median incomes by block group from the 2014–2018 ACS, data on economic mobility by Census tract and county from the Opportunity Atlas 72 , and measures of county-level and ZIP-level characteristics, such as the share of the population by race and ethnicity and the share of single parents, from the ACS and the Census. We describe those data in detail in Supplementary Information A.5.
We construct the following sets of variables for each person in our analysis sample. We measured these variables on 28 May 2022.
The data contain information on all friendship links between Facebook users. We focus only on friendships within our analysis sample; that is, we exclude friendships with people aged below 25 years or above 44 years, people who live outside the United States or people who do not satisfy one of our other criteria for inclusion in the analysis sample.
Facebook friendship links need to be confirmed by both parties, and most Facebook friendship links are between individuals who have interacted in person 85 . The Facebook friendship network can therefore be interpreted as providing data on people’s real-world friends and acquaintances rather than purely online connections. Because individuals tend to have many more friends on Facebook than they interact with regularly, we also verify that our results hold when focusing on an individual’s ten closest friends, where closeness is measured on the basis of the frequency of public interactions such as likes, tags, wall posts and comments.
Following prior work 86 , we use location data to construct statistics at various geographical levels. Every individual is assigned a residential ZIP code and county based on information and activity on Facebook, including the city reported on Facebook profiles as well as device and connection information. Formally, we use 2010 Census ZIP code tabulation areas (ZCTAs) to perform all geographical analyses of ZIP-code-level data. We refer to these ZCTAs as ZIP codes for simplicity. According to the 2014–2018 ACS, there are 219,214 Census block groups, 32,799 ZIP codes and 3,220 counties, with average populations of 1,488, 9,948 and 101,332 in each respective geographical designation.
We construct a model that generates a composite measure of socioeconomic status (SES) for working-age adults (individuals between the ages of 25 and 64 years) that combines various characteristics. We construct our baseline SES measure in three steps, which are described in greater detail in Supplementary Information B.1.
First, for Facebook users who have location history (LH) settings enabled, we use the ACS to collect the median household income in their Census block group. LH is an opt-in setting for Facebook accounts that allows the collection and storage of location signals provided by a device’s operating system while the app is running. We observe Census block groups from individuals in the LH subsample. By contrast, we can only assign ZIP codes to individuals who do not have LH enabled. If an individual subsequently opts out of LH, their previously stored location signals are not retained.
Second, we estimate a gradient-boosted regression tree to predict these median household incomes using variables observed for all individuals in our sample, such as age, sex, language, relationship status, location information (ZIP code), college, donations, phone model price and mobile carrier, usage of Facebook on the Internet (rather than a mobile device), and other variables related to Facebook usage listed in Supplementary Table 4. We use this model to generate SES predictions for all individuals in our sample.
Finally, individuals (including the LH users in the training sample) are assigned percentile ranks in the national SES distribution on the basis of their predicted SES relative to others in the same birth cohort.
We do not use any information from an individual’s friends to predict their SES, which ensures that errors in the SES predictions are not correlated across friends, which would bias our estimates of homophily by SES. We also do not use direct information on individuals’ incomes or wealth, as we do not observe these variables at the individual level in our data. However, we show below that our measures of SES are highly correlated with external measures of income across subgroups.
The algorithm described above is one of many potential ways of combining a set of underlying proxies for SES into a single measure. To verify that our findings are not sensitive to the specific variables or algorithm used to predict SES, we show that our results are similar when we use a simple unweighted average of z-scores of the underlying proxies or when we directly use ZIP code median household incomes for all users, eschewing the prediction model and other proxies entirely (Supplementary Table 5).
We link individuals in our primary analysis sample to their parents (who may not be in the analysis sample themselves) to construct measures of family SES during childhood. To link individuals to their parents, we use self-reported familial ties, a hash of user last names, and public user-generated wall posts and major life events (see Supplementary Information A.2 for details). We then use the SES of parents, constructed using the algorithm described above, to assign parental SES to individuals. Finally, we assign individuals a parental SES rank on the basis of their predicted parental SES, ranking individuals on the basis of parental SES relative to others in the same birth cohort. We are able to assign parental SES ranks for 31% of the individuals in our primary analysis sample.
To identify friendships made in high school, we first use self-reports to assign individuals to schools. For people who do not report a high school, we use data on their friendship networks to impute those groups (see Supplementary Information A.3 for details). For the 3.3% of users who report multiple high schools, we select the school in which the user has the largest number of friends. This process produces information on high schools for 74.9% of individuals in our analysis sample. Finally, if an individual and one of their friends attended the same high school within three cohorts of each other, we identify them as high school friends.
Extended Data Table 4a shows summary statistics for our baseline sample and, for comparison, for those aged between 25 and 44 years in the 2014–2018 ACS. The Facebook sample is similar to the full population in terms of age, sex and language. Consistent with previous work 87 , women are slightly over-represented in our Facebook sample (53.6%) relative to men. The median individual in our analysis sample has 382 in-sample Facebook friends; in total, there are just under 21 billion friendship pairs between individuals in the sample.
As much of our analysis relies on variation across areas, it is important that our sample has good coverage not just nationally but also across locations. In Supplementary Information A.1, we show that our sample has high coverage rates across the United States, and that coverage rates do not vary systematically across locations with different income levels or demographic characteristics.
Most of our analysis draws on the SES measure constructed as described in the previous subsection. We evaluate the accuracy of this SES measure by correlating the share of households with above-median income within each ZIP code from the ACS with the estimated share of Facebook users with above-median SES in our sample. The population-weighted correlation between our estimates of the share of high-SES individuals and the ACS estimates at the ZIP-code level is 0.88. Furthermore, there are similarly high correlations between our estimates of the share of high-SES households and corresponding statistics drawn from external publicly available administrative datasets at the high school and college levels (see the companion paper 9 for details).
For some parts of our analysis—in particular, for computing measures of EC during childhood—we focus on the subsample of individuals whom we can link to parents with an SES prediction and whom we can assign to a high school on the basis of self-reports and network-based imputations. Panel B of Extended Data Table 4 presents summary statistics for this subsample of 19.4 million users, or about 27% of the full analysis sample. The characteristics of this subsample are broadly similar to those of the full sample, although users whom we can link to high schools and parents with SES predictions are about 2 years younger on average than users in the full sample, in large part because our approach does not allow us to assign SES predictions for parents older than 65 years. County-level median household incomes differ by $876 between the samples, about 6% of a standard deviation.
We further evaluate our SES measure and parental linkages by comparing estimates of intergenerational economic mobility using our SES proxies to publicly available estimates based directly on household incomes from population-level tax data. There is a linear relationship between individuals’ and their parents’ SES ranks across the distribution of parental SES, with a slope of 0.32 (Extended Data Fig. 2) This relationship is similar to the estimated slope of 0.34 in population tax data 10 , thereby supporting the validity of both our SES imputations and parental linkages.
We conclude that our Facebook analysis samples are representative of the populations we seek to study and that our measures of SES align with external data.
denote individual i’s share of friends from SES quantile Q. To obtain measures of the degree of homophily that are not sensitive to the size of each quantile bin, we normalize fQ,i by the share of individuals in the sample who belong to quantile Q, wQ (for example, wQ = 0.1 for deciles). We then define person i’s individual EC (IEC) to individuals from quantile Q as
$$>>_\equiv \frac_>_>.$$We define the level of EC in community (county or ZIP code) c as the mean level of individual EC of low-SES (for example, below-median) members of that community, as follows: $$>>_=\frac_We construct standard errors for EC in each location using a bootstrap resampling method that adjusts for correlations in connectedness across individuals arising from having common pools of friends (Supplementary Information B.3). Because sample sizes are large, almost none of the geographical difference in EC is due to sampling variation. At the county level, the mean standard error of 0.004 is more than an order of magnitude smaller than the signal standard deviation of EC across counties of 0.18. When we randomly split the microdata into two halves and estimate ECs by county in each half, we obtain a split-sample correlation (reliability) of 0.999 across counties, weighting by the number of people in each county with household income below the national median. The ZIP-code-level estimates we release are also precise, with a split sample reliability of 0.99 (pooling all ZIP codes in the United States) when weighted by below-median-income population.
We construct two measures of childhood EC: one based on links between individuals and their parents in our Facebook analysis sample and another based on data from Instagram.
To measure childhood EC in the Facebook sample, we restrict the sample to individuals whom we could link to high schools and their parents (about 27% of the full sample). We assign parental SES ranks (estimated using the machine-learning algorithm described in the ‘Variable definitions’ section) within this subsample, ranking individuals on the basis of parental SES relative to others in the same birth cohort. We then measure fQ,i as the share of friends from parental-SES quantile Q within the subset of friends from high school: friends who attended the same high school and are within three cohorts of the individual (so that they would have most likely overlapped in school). Ideally, we would directly observe all friendships made during childhood. However, because the Facebook platform was not available when the members of the birth cohorts we analyse were growing up, we use current friends who attended the same high school to identify friendships made in childhood. When calculating childhood EC by location, we assign individuals to the counties where their high schools are located, rather than counties where they currently live, to map people to the places where they grew up. We do not produce ZIP-code-level measures of childhood EC because we cannot reliably infer individuals’ childhood ZIP codes from the locations of their high schools (as children from many ZIP codes might attend a given school).
To measure childhood EC for users of Instagram, a widely used social networking platform owned by Meta, we restrict the raw Instagram data to personal users (not business pages) in the United States who had not deactivated their account, been active on the platform within the past 30 days, and were predicted to be between 13 and 17 years of age as of 28 May 2022 (see Supplementary Information A.4 for further details). Next, we assign the individuals in our sample to ZIP codes on the basis of their IP address and other features. Then, we assign Instagram users an SES estimate on the basis of two variables: (1) the median household income of their residential ZIP code from publicly available data on incomes in the 25–44-year age bin from the 2014–2018 ACS, and (2) the price of their phone. We then construct a weighted z-score of these two inputs, placing two-thirds of the weight on median household income and one-third of the weight on the price of the phone. The higher weight on ZIP-code-based income relative to phone price reflects that ZIP codes played a particularly large role in the machine-learning model used to construct our baseline measures of SES in the Facebook data (although using other weights in the construction of the z-score produced similar results). We rank users nationally on the basis of these weighted z-scores to assign them a SES percentile rank. Users above the 50th percentile are termed high SES, whereas those at the 50th percentile and below are termed low SES. Finally, we construct measures of individual EC as defined in equation (2). Because ties on Instagram, which are termed ‘follows’, are directional—that is, one person can follow another without that person following them—we restrict our attention to reciprocal followers to mimic friendships on Facebook when measuring connectedness.
Each of the two measures of childhood EC has certain advantages and limitations. The Facebook parental SES measure has the advantage of capturing the childhood friendships of individuals in approximately the same set of cohorts for which we measure economic mobility. However, because we are able to construct this measure only for the 27% of individuals for whom we can link to parents and who report their high school, these estimates are noisier and potentially less representative than our baseline estimates. The Instagram data do not require parental linkage and capture all friends, not just high school friends, thereby producing a larger and more comprehensive sample. The limitation of the Instagram EC measure is that it measures EC among the 2005–2009 birth cohorts, rather than the 1978–1983 cohorts for which we measure economic mobility. However, the stability of both economic mobility 72 and EC (Supplementary Fig. 1) within a location over time mitigates the consequences of this misalignment.
We represent a set of friendships by the matrix A ∈ n×n , where Aij = 1 denotes the existence of a friendship (edge) between individuals i and j, and Aij = 0 denotes the absence of a friendship. We focus on three measures of the structure of A: clustering and support ratio, which are measures of local correlation in friendships, and spectral homophily, a measure of overall network fragmentation. Other measures of cohesiveness, such as algebraic connectivity 88 , are also informative, but are difficult to compute or even approximate for networks of the scale we analyse. The three measures of cohesiveness we focus on here have the advantage of being computationally tractable in large samples.
Previous work 33 has argued that if person i is friends with both persons j and k, then having j and k be friends with each other can help them collectively pressure and sanction person i, thereby helping to enforce norms. Motivated by this logic, many studies have measured the extent of such ‘network closure’ by the degree of clustering within a person’s network: the frequency with which two friends of that person are in turn friends with each other. Letting Ni(A) denote the set of i’s friends and di(A) its cardinality (the number of friends i has), the clustering of i’s network is defined as
We measure clustering in a community c as the average of equation (4) across people living in that community as follows: